from urllib.request import urlopen
from urllib.request import Request
from bs4 import BeautifulSoup
import re
import time
import datetime
def getWeibo(userWeiboID,pageIndex):
global weiboIndex
global mdContent
url = 'http://weibo.cn/u/%s?page=%d'%(userWeiboID,pageIndex)
header = {
"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36",
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"Upgrade-Insecure-Requests" : "1",
"Accept" :"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language":"zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4,ja;q=0.2",
"Cookie": "这里填写你的 Cookie 值"
}
request = Request(url,None,header)
response = urlopen(request,timeout=1000)
bsObj = BeautifulSoup(response.read(),"html.parser")
cardListElement = bsObj.find_all("div",{"class":"c"})
print(url)
for cardElement in cardListElement:
if cardElement.get('id') is None:
continue
if cardElement.find("span",{"class":"kt"}) is not None:
continue
timeLongStr = cardElement.find("span",{"class":"ct"}).get_text()
timeArray = timeLongStr.split('\xa0')
timeStr = timeArray[0]
seperatorArray = timeStr.split('-')
if len(seperatorArray) == 1:
structTime = time.localtime(time.time())
currentTime = datetime.datetime.now()
currenStructTime = yesterdayCurrentTime.timetuple()
currenYear = currenStructTime.tm_year
timeStr = str(currenYear) + '年' + timeStr
timeStr = timeStr.replace('年','-')
timeStr = timeStr.replace('月','-')
timeStr = timeStr.replace('日','')
colonArray = timeStr.split(':')
if len(colonArray) == 2:
timeStr = timeStr + ':00'
try:
weiboCreateTimeArray = time.strptime(timeStr, "%Y-%m-%d %H:%M:%S")
createdTimestamp = int(time.mktime(weiboCreateTimeArray))
print("timeStr:",timeStr)
print('createdTimestamp:',str(createdTimestamp))
print('yesterdayStartTimeStamp:',str(yesterdayStartTimeStamp),' yesterdayEndTimeStamp:',str(yesterdayEndTimeStamp))
if createdTimestamp > yesterdayEndTimeStamp:
continue
if createdTimestamp < yesterdayStartTimeStamp:
return
except Exception as err:
print("timeStr:",timeStr)
print(err)
continue
repostCountStr = '0'
repostItems = cardElement.find_all('a',{'href': re.compile('http://weibo.cn/repost/*')})
for repost in repostItems:
repostCountLongStr = repost.get_text()
repostCountStr = repostCountLongStr[3:len(repostCountLongStr) - 1]
print('转发数量:',repostCountStr,'\n\n')
repostWeiboRepostCountStr = '0'
for i,cmt in enumerate(cardElement.find_all("span",{"class":"cmt"})):
if i == 2:
repostWeiboRepostCountLongStr = cmt.get_text()
repostWeiboRepostCountStr = repostWeiboRepostCountLongStr[5:len(repostWeiboRepostCountLongStr) - 1]
print('转发微博的转发数量:',repostWeiboRepostCountStr,'\n\n')
if int(repostCountStr) + int(repostWeiboRepostCountStr) < 20:
continue
weiboContent = ""
haveRetweetWeibo = False
if len(cardElement.find_all(text='转发理由:')) != 0:
haveRetweetWeibo = True
if haveRetweetWeibo:
repostReasonItems = cardElement.find_all('a',{'href': re.compile('http://weibo.cn/attitude/*')})[0].previous_siblings;
for index,repostReasonItem in enumerate(repostReasonItems):
weiboContent = repostReasonItem.string + weiboContent;
weiboContent = weiboContent[5:]
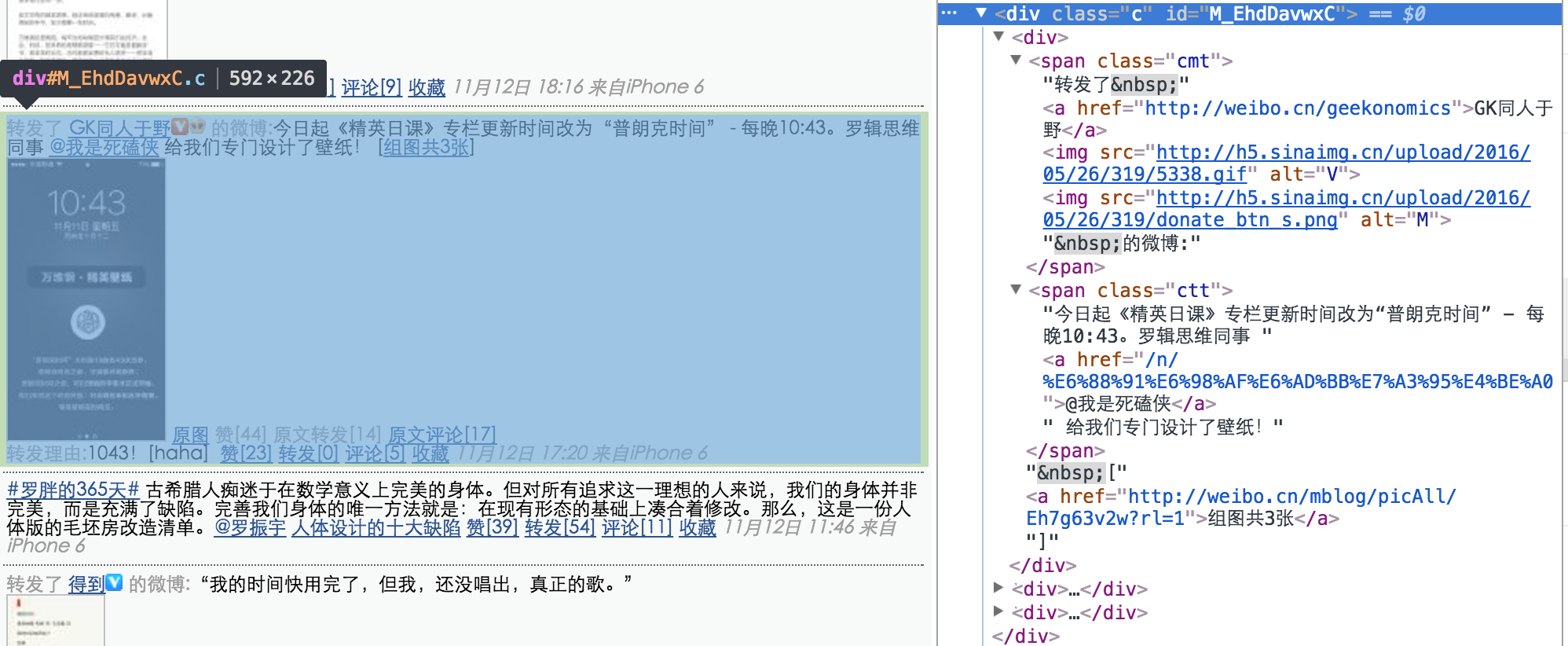
weiboContent = weiboContent + '\n\n' + str(cardElement.find("span",{"class":"ctt"}))
else:
weiboContent = str(cardElement.find("span",{"class":"ctt"}))
weiboURL = ""
for ccA in cardElement.find_all("a",{"class":"cc"}):
weiboURL = ccA["href"]
url1 = weiboURL.replace('weibo.cn','m.weibo.cn')
url1Array = url1.split('=')
uidArray = url1Array[1].split('&')
uid = uidArray[0]
weiboURL = url1.replace('comment',uid)
weiboURL = re.sub(r'\?uid[\s\S]*','',weiboURL)
weiboIndex += 1
mdContent = mdContent + '## ' +str(weiboIndex) + '.' + weiboContent + '\n\n' + '<' + weiboURL + '>\n\n' + timeStr + '\n\n'
pageIndex += 1
getWeibo(userWeiboID,pageIndex)
for day in range(1):
structTime = time.localtime(time.time())
yesterdayCurrentTime = datetime.datetime.now() - datetime.timedelta(days=day+1)
yesterdayStructTime = yesterdayCurrentTime.timetuple()
yesterdayYear = yesterdayStructTime.tm_year
yesterdayMonth = yesterdayStructTime.tm_mon
yesterdayDay = yesterdayStructTime.tm_mday
yesterdayStartTime = "%d-%d-%d 00:00:00"%(yesterdayYear, yesterdayMonth, yesterdayDay)
yesterdayStartTimeArray = time.strptime(yesterdayStartTime, "%Y-%m-%d %H:%M:%S")
yesterdayStartTimeStamp = int(time.mktime(yesterdayStartTimeArray))
yesterdayEndTime = "%d-%d-%d 23:59:59"%(yesterdayYear, yesterdayMonth, yesterdayDay)
yesterdayEndTimeArray = time.strptime(yesterdayEndTime, "%Y-%m-%d %H:%M:%S")
yesterdayEndTimeStamp = int(time.mktime(yesterdayEndTimeArray))
weiboIndex = 0;
fileName = str(yesterdayYear) + "-" + str(yesterdayMonth) + '-' + str(yesterdayDay)
mdContent = '# ' + fileName + '\n\n'
userWeiboDic = {
"唐巧_boy" : "1708947107",
"onevcat" : "2210132365",
"iOS程序犭袁" : "1692391497",
"没故事的卓同学" : "1926303682",
"叶孤城___" : "1438670852",
"我就叫Sunny怎么了" : "1364395395",
"nixzhu" : "2076580237",
"ibireme" : "2477831984",
"bang" : "1642409481",
"KITTEN-YANG" : "2854163804",
"StackOverflowError" : "1765732340",
"图拉鼎" : "1846569133",
"lzwjava" : "1695406573",
"董宝君_iOS" : "3026163601",
"移动开发前线" : "5861126740"
}
for name,weiboID in userWeiboDic.items():
print("-------正在爬取 %s 的微博------"%name)
getWeibo(weiboID,1)
filePath = './notes/' + fileName + '.md'
print('filePath:',filePath,'mdContent:',mdContent)
f = open(filePath,mode='w',encoding="UTF-8")
f.write(mdContent)
f.close()
print('爬取完毕')