最近看到各大牛,都在捣鼓 Python。本着羡慕嫉妒恨的节奏,也热闹下。公司有个北大女医学博士,人家都会用 Python 写东西。跟着学习下,整理下这几天学到的东西和遇到的问题。
安装 Python
官网下载
Downloads 按钮很明显也很智能,根据你当前的系统,给你推荐下载哪一个。如下图:
选择 Python 版本
Python 3.X 和 Python 2.X 到底该选择哪个?
听别人说改动挺大,本着跟准新技术的原则,我选择的是 Python 3.X。
学习教程
官方教程
官方库
第三方库
3.X 和 2.X版本的区别
pip
pip 是啥,类似 iOS 开发中的 CocoaPods,类库管理工具。
如何安装 pip,需自备梯子
如何使用 pip
我在安装的过程中,安装成功,但出现了一个没有 pip 这个命令的问题,应该是还没安装成功的原因吧。下方答案虽然没打对号,但是用这个sudo easy_install pip命令,就解决了。
StackOverFlow 上的解决方法
4.Get/POST 请求数据
GET 请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| import urllib.request import urllib data = {} data['id'] = '1' urlStr = 'http://XXX' urlParameters = urllib.parse.urlencode(data) print(urlParameters) fullURLString = urlStr + '?' + urlParameters resp = urllib.request.urlopen(fullURLString) responseStr = resp.read() responseDecodeStr = responseStr.decode("utf8") print(responseDecodeStr)
|
POST 请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| import urllib.request import urllib data = {} data['id'] = '1' urlStr = 'http://XXX' urlParameters = urllib.parse.urlencode(data) postdata = urlParameters.encode('utf-8') print(urlParameters) response = urllib.request.urlopen(urlStr,postdata) responseStr = response.read() responseDecodeStr = responseStr.decode("utf8") print(responseDecodeStr)
|
爬虫 1:查找一个网站所有的链接地址
这个例子是这里面的,光看不敲,不是做技术的态度。参照他的,自己写一哈,不如他写的好,好多东西没考虑到。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
| import urllib.request import urllib from bs4 import BeautifulSoup from collections import deque urlStr = 'http://www.douban.com' spiderQueue = deque() spiderQueue.append(urlStr) visitedSet = set() while spiderQueue: urlStr = spiderQueue.popleft() print (urlStr) try: response = urllib.request.urlopen(urlStr) responseStr = response.read() soup = BeautifulSoup(responseStr) linksArray = soup.findAll('a') for link in linksArray: hrefStr = link.get('href') print('链接地址 ' + hrefStr + '\n') if 'http' in hrefStr and hrefStr not in visitedSet: visitedSet |={hrefStr} spiderQueue.append(hrefStr) print('加入队列 ---> ' + hrefStr + '\n') except: print('遇到异常') continue
|
爬虫2:爬妹子图片
这个可能有点邪恶,是这篇文章教我的, 我多添加了些代码。可以爬出这个豆瓣妹子网站的所有图片。可以再优化下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
| import urllib.request import urllib from bs4 import BeautifulSoup while 1: pageNumber = 1 urlStr = 'http://dbmeizi.com/?p=' + str(pageNumber) response = urllib.request.urlopen(urlStr) responseStr = response.read() soup = BeautifulSoup(responseStr) liTagsArray = soup.findAll('li',attrs = {'class':'span3'}) for li in liTagsArray: imageTags = li.findAll('img') for image in imageTags: imageLink = image.get('data-bigimg') imageName = image.get('data-id') fileSavePath = '/Users/iYiming/Downloads/meizi/%s.jpg' % imageName urllib.request.urlretrieve(imageLink,fileSavePath) print (fileSavePath) pageNumber += 1 urlStr = 'http://dbmeizi.com/?p=' + str(pageNumber)
|
展示下爬到的东西:
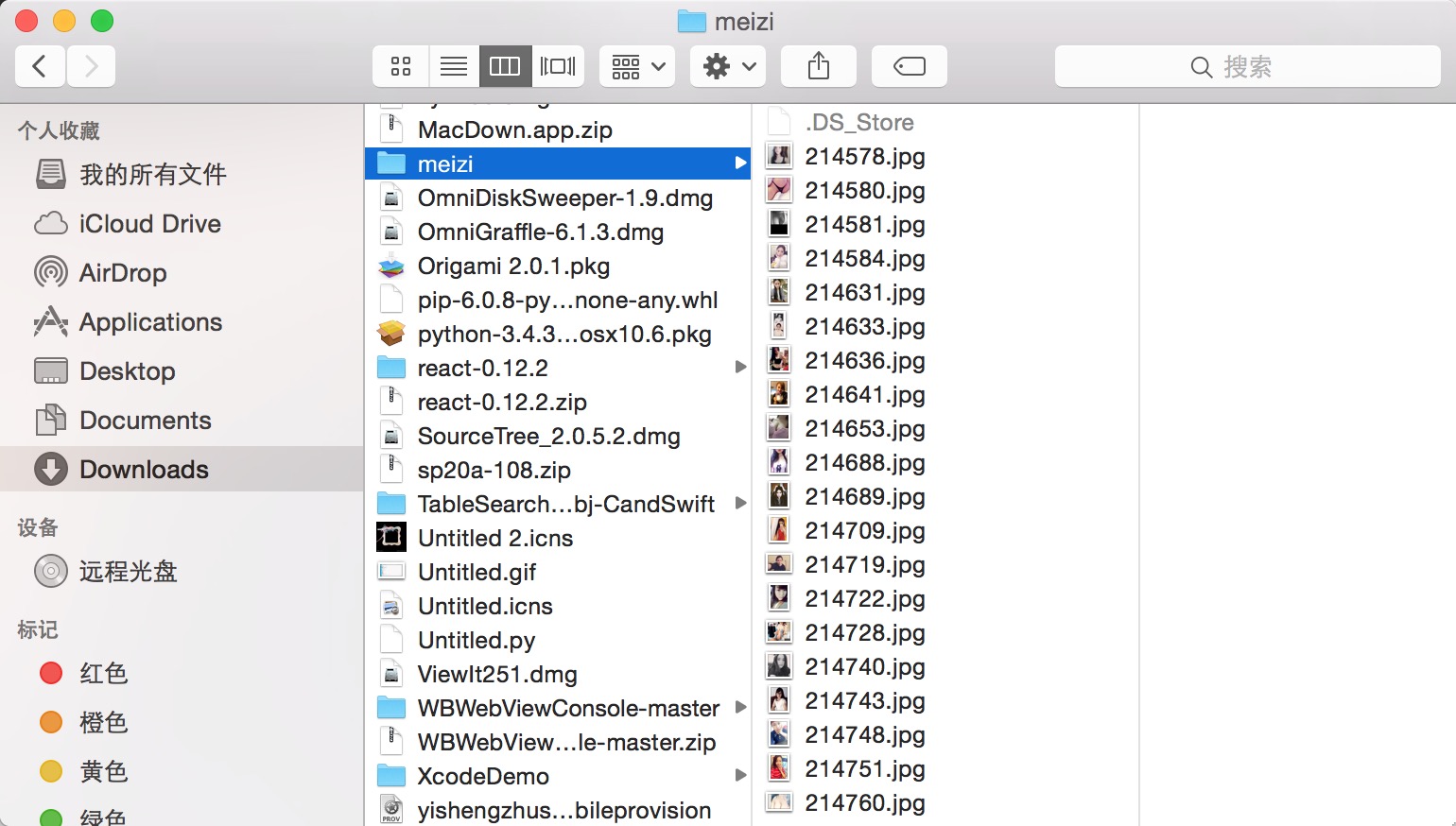
其他
一个不错教程:用 Python 3 开发网络爬虫
中间遇到的问题:
Python 3.4 版本 和 2.7 版本的不同
IDLE 中不能输入中文的问题
有疑惑的问题
0.IDLE 如何带自动提示,太难受了
1.没有提示,这么多类库,怎么用?
感谢上面所有链接的作者!
